When building modern software, third-party APIs are often the unsung heroes powering everything from email delivery to data enrichment. But while integrating a handful of SaaS tools might feel like a breeze during their generous free trials, things can quickly change once those trials run out. That’s exactly what happened to us with a seemingly “tiny” SaaS tool that turned into an unexpectedly stubborn roadblock—and the lessons we learned along the way will help you keep your own APIs humming, even when they start pushing back.
TL;DR
After the free trial expired on a small SaaS platform we used, our previously seamless API integration began hitting rate limits and throttles. We quickly needed a reliable retry + exponential backoff mechanism to avoid breaking our system’s workflows. In this post, I’ll share what most developers miss about API behavior after trials end, and the precise retry pattern that kept our integrations stable. You’ll also get reusable logic and best practices you can apply across any API client.
The honeymoon ends with free trials
During the free trial of the SaaS tool—let’s call it “MicroStats”—our backend integrations ran flawlessly. We pulled usage metrics every minute and piped them into our dashboard with zero pushback from their servers. However, the moment the free tier turned into a paid “starter” plan, we began to see errors: timeouts, 429 (“Too Many Requests”) responses, and even full-blown service denials.
This was surprising at first. The documentation hadn’t changed, and there was no mention of differing rate limits between free trials versus starter plans. Unfortunately, reality painted a different picture.
- Error Rate Jump: Our 2% API error rate spiked to over 35% within hours.
- Integration Breakdown: Analytics stopped updating at crucial times of the day.
- Support Bottlenecks: We waited 48 hours for a response explaining the throttling.
If you’re thinking, “Why not just upgrade to a better plan?”, we considered it. But budget constraints and unclear pricing tiers made that a premature move. We needed a technical fix—and fast.
Why do SaaS APIs throttle after a trial?
It turns out many SaaS platforms use trial environments with relaxed rules to give users a full “taste” of product capabilities. But once a real plan kicks in, production settings apply—often without the user realizing it. Throttling is also more aggressive on entry-tier plans to protect multi-tenant performance and infrastructure budgets.
In the case of MicroStats, the trial plan allowed up to 120 requests per minute per user. The starter plan allowed only 15. Unfortunately, no automated alert or dashboard indicated we were hitting this limit—until things broke.
So we built our own adaptive retry and backoff strategy to stay within bounds.
The retry + exponential backoff pattern that saved the day
When making requests to an unstable or throttled API, simplicity won’t save you. A naïve retry approach like “try again immediately” just makes the problem worse. We wanted a solution that was intelligent, graceful, and able to adjust over time. Here’s what worked:
Core retry logic:
- Detect when a request failed due to a rate limit (HTTP 429) or timeout.
- Wait before retrying—starting with a small delay and increasing it over time.
- Limit how many retries we attempt.
- Use randomness (a little “jitter”) to avoid retry storms.
Here is the algorithm we implemented in pseudocode:
function make_request_with_backoff(url):
max_retries = 5
base_delay = 1 # seconds
for attempt in range(max_retries):
response = send_http_request(url)
if response.success:
return response.data
elif response.status in [429, 503]:
delay = base_delay * (2 attempt)
jittered_delay = delay * (0.8 + random(0.4)) # add jitter
sleep(jittered_delay)
else:
raise Exception(response.error)
raise Exception("Max retries reached")
This exponential backoff strategy is a common and reliable pattern used by systems like AWS SDKs, Google Cloud APIs, and the Kubernetes control plane. It’s designed to make integration resilient, even when an API is aggressively throttling traffic.
Jitter: the secret ingredient
Adding jitter (a small random delay variation) is essential in distributed environments. Imagine 100 systems all retrying after exactly 2 seconds—the API will get flooded again. Jitter distributes retry attempts to reduce spikes.
Here are three common jitter strategies:
- Full jitter: Pick a random delay between 0 and the max backoff (best for high traffic systems).
- Equal jitter: Backoff = base + random(0, base) (balances stability and randomness).
- Decorrelated jitter: Randomized delay based on prior backoff; Amazon SQS uses this.
We picked equal jitter because we wanted predictable behavior with enough randomness to avoid traffic clumps.
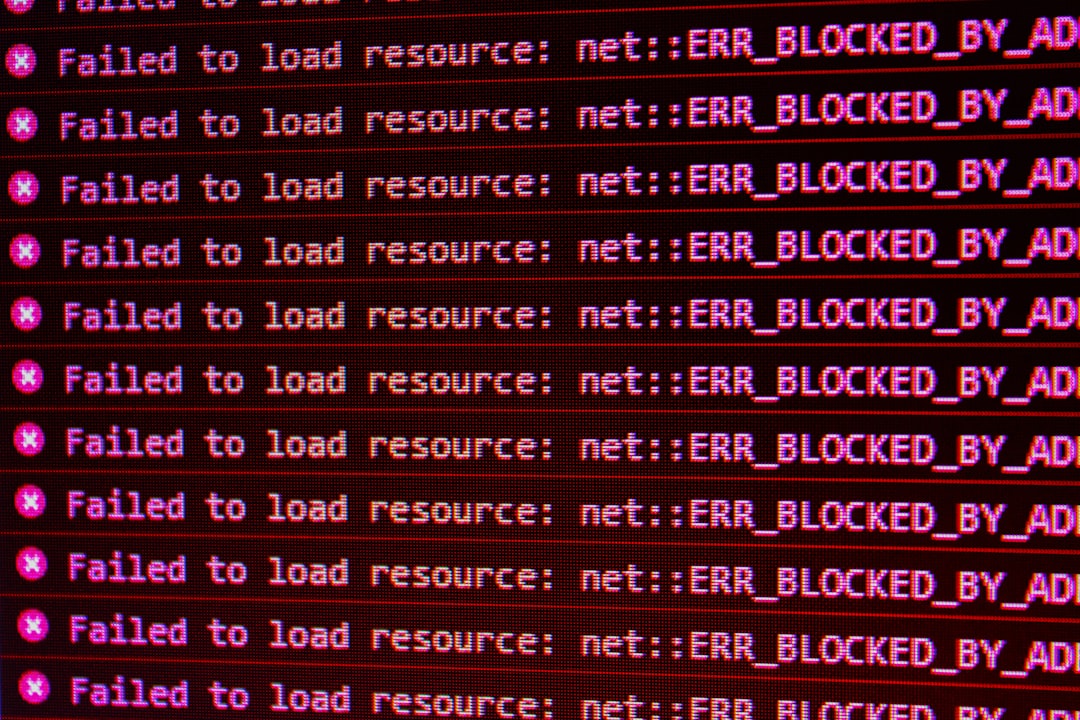
How we handled persistent failures
Even the best retry logic won’t save you from an API that’s completely overloaded or under a hard limit. So we added two key safeguards:
- Persistent queue: Failed requests are queued in a background job system for retry later. This prevents failures from blocking main workflows.
- Alerting: If the error rate is above threshold (e.g., 10% over 5 minutes), we get an alert. This lets us act fast if things go sideways.
These additions made the entire integration hands-free, allowing us to sleep well knowing retries were happening responsibly and detectably.
Bonus: Caching and prefetching helped too
To further reduce load on MicroStats’s API, we began caching frequent responses. Usage data doesn’t change every second, so caching stats for even 30 seconds cut our total API calls by over 50%!
Meanwhile, we also added prefetching. If we knew a dashboard refresh was likely, a background job would proactively fetch data into the cache moments before user interaction.

A few final lessons to future-proof your API calls
Looking back, here’s what we’ve learned—and what you can apply too:
- Never assume free trials match production performance. Ask vendors for rate limits early.
- Log and track 429 + 503 errors. These are early signals before integrations fail.
- Implement exponential backoff early. Even if you haven’t hit limits—yet.
- Alert on error trends, not just failures. Spiking errors are often a canary for bigger issues.
- Consider a queue and retry mechanism for all critical API endpoints. Your future self will thank you.
Conclusion
Integrating with third-party APIs is easy until it’s not. When MicroStats throttled us after a cheerful free trial, we learned how important robust retry patterns and adaptive backoff strategies really are. By using exponential backoff with jitter, a persistent retry system, and intelligent caching, we turned a cascading failure into a self-healing system.
Whether you’re just getting started with SaaS APIs or scaling to handle thousands of requests per minute, these practices can help you build integrations that don’t just work—they resist failure. And that resilience? That’s the real job of a software engineer.